
This paper identifies trends in the application of big data in the transport sector and categorizes research work across scientific subfields. The systematic analysis considered literature published between 2012 and 2022. A total of 2671 studies were evaluated from a dataset of 3532 collected papers, and bibliometric techniques were applied to capture the evolution of research interest over the years and identify the most influential studies. The proposed unsupervised classification model defined categories and classified the relevant articles based on their particular scientific interest using representative keywords from the title, abstract, and keywords (referred to as top words). The model’s performance was verified with an accuracy of 91% using Naïve Bayesian and Convolutional Neural Networks approach. The analysis identified eight research topics, with urban transport planning and smart city applications being the dominant categories. This paper contributes to the literature by proposing a methodology for literature analysis, identifying emerging scientific areas, and highlighting potential directions for future research.
Avoid common mistakes on your manuscript.
Urbanization, ongoing changes in mobility patterns, and rapid growth in freight transportation pose significant challenges to stakeholders and researchers within the transportation sector. New policies have focused on promoting sustainability and reducing emissions through smart and multimodal mobility [1]. To address these challenges, authorities are developing strategies that employ technological advances to gain a deeper understanding of travel behavior, produce more accurate travel demand estimates, and enhance transport system performance.
Undoubtedly, the development of Intelligent Transport Systems (ITS) and recent advances in Information and Communication Technology (ICT) have enabled the continuous generation, collection, and processing of data and the observation of mobility behavior with unprecedented precision [2]. Such data can be obtained from various sources, including ITS, cell phone call records, smart cards, geocoded social media, GPS, sensors, and video detectors.
Over the past decade, there has been increasing research interest in the application of big data in various transportation sectors, such as supply chain and logistics [3], traffic management [4], travel demand estimation [5], travel behavior [6], and real-time traffic operations [7]. Additionally, numerous studies in the field of transport planning and modeling have applied big data to extract vital attributes including trip identification [8] and activity inference [9]. Despite research efforts and existing applications of big data in transportation, many aspects remain unknown, and the prospects of big data to gain better insights into transport infrastructure and travel patterns have not yet been explored.
To maximize the benefits of big data in traffic operations, infrastructure maintenance, and predictive modeling, several challenges remain to be addressed. These include handling the high velocity and volume of streaming data for real-time applications, integrating multiple data sets with traditional information sources, ensuring that the data is representative of the entire population, and accessing big data without compromising privacy and ethical concerns. In terms of transport modeling and management, the research focuses on achieving short-term stability by incorporating more comprehensive data sets that cover hourly, daily, seasonal, or event-based variations, and on enhancing mobility on demand through real-time data processing and analysis. Additionally, it has become necessary to further investigate the methodology for processing large amounts of spatial and temporal information that has primarily been intended for non-transport purposes and to reconsider the existing analytical approaches to adapt to the changing data landscape.
There is an intention among policymakers, transport stakeholders, and researchers to better understand the relationship between big data and transport. The first step in this direction is to identify the key areas of big data utilization in the transport sector. Therefore, this study attempts to map big data applications within the transport domain. It provides a broad overview of big data applications in transport and contributes to the literature by introducing a methodology for identifying emerging areas where big data can be successfully applied and subfields that can be further developed.
The scope of the current study is twofold. First, a holistic literature analysis based on bibliometric techniques complemented by a topic classification model covering the complete domain of big data applications in the transportation sector was implemented. Despite numerous studies attempting to review the relevant literature, such as big data in public transport planning or transport management [10, 11] to the best of our knowledge, no such investigation has produced a comprehensive and systematic cluster of multiple big data applications across the entire transportation domain based on a significant number of literature records. Therefore, the primary objective of this study is to classify the literature according to its particular interest and to pinpoint evolving scientific subfields and current research trends.
Second, as multiple studies have been conducted in this domain, the need to identify and assess them prior to running one’s own research through a thorough literature review is always necessary. However, the analysis and selection of appropriate studies can be challenging, particularly when the database is large. Therefore, this study aims to provide a comprehensive approach for evaluating and selecting appropriate literature that could be a methodological tool in any research field. Bibliometric methods have been widely applied in several scientific fields. Most of these studies use simple statistical methods to determine the evolution of the number of publications over the years, authors’ influence, or geographical distribution. There are also research works that attempt to categorize the literature mainly by manual content analysis [12, 13] or by co-citation analysis, applying software for network and graphical analyses [14, 15]. In this study, the review process also included an unsupervised topic model to classify literature into categories.
This paper presents a comprehensive evaluation of up-to-date published studies on big data and their applications in the transportation domain. A total of 2671 articles from Elsevier's Scopus database, published between 2012 and 2022 were analyzed. Bibliometric techniques were applied to capture the evolution of research over time and uncover emerging areas of interest. In addition, the focus of this study is to define categories and classify relevant papers based on their scientific interests. To achieve this, unsupervised classification was applied using the topic model proposed by Okafor [16] to identify clusters, extract the most representative topics, and group the documents accordingly.
The current study attempts to answer the following questions:
This paper consists of six sections. Following the introduction, Sect. 2 provides a summary of previous research in this subject area. Section 3 outlines the methodology applied in this research. This includes the process of defining the eligible studies, bibliometric techniques utilized, and the topic model employed for paper classification. Section 4 presents the initial statistical results and the classification outcomes derived from the topic model. In Sect. 5, the findings are summarized, and the results associated with the research questions are discussed. The final Section presents the general conclusions and research perspectives of the study.
Due to the significant benefits of big data, several studies have been conducted in recent years to review and examine the existing applications of different big data sources in transportation. Most of these focus on a specific transport domain, such as transport planning, transport management and operations, logistics and supply chain and Intelligent Transportation Systems.
In the context of transport planning and modeling, Anda et al. [2] reviewed the current application of historical big data sources, derived from call data records, smart card data, and geocoded social media records, to understand travel behavior and to examine the methodologies applied to travel demand models. Iliashenko et al. [17] explored the potential of big data and Internet of Things technologies for transport planning and modeling needs, pointing out possible applications. Wang et al. [18] analyzed existing studies on travel behavior utilizing mobile phone data. They also identified the main opportunities in terms of data collection, travel pattern identification, modeling and simulation. Huang et al. [19] conducted a more specialized literature review focusing on the existing mode detection methods based on mobile phone network data. In the public transportation sector, Pelletier et al. [20] focused on the application of smart card data, showing that in addition to fare collection, these data can also be used for strategic purposes (long-term planning), tactical purposes (service adjustment and network development), and operational purposes (public transport performance indicators and payment management). Zannat et al. [10] provided an overview of big data applications focusing on public transport planning and categorized the reviewed literature into three categories: travel pattern analysis, public transport modeling, and public transport performance assessment.
In traffic forecasting, Lana et al. [21] conducted a survey to evaluate the challenges and technical advancements of traffic prediction models using big traffic data, whereas Miglani et al. [22] investigated different deep learning models for traffic flow prediction in autonomous vehicles. Regarding transport management, Pender et al. [23] examined social media use during transport network disruption events. Choi et al. [11] reviewed operational management studies associated with big data and identified key areas including forecasting, inventory management, revenue management, transportation management, supply chain management, and risk analysis.
There is also a range of surveys investigating the use of big data in other transport subfields. Ghofrani et al. [24] analyzed big data applications in railway engineering and transportation with a focus on three areas: operations, maintenance, and safety. In addition, Borgi et al. [25] reviewed big data in transport and logistics and highlighted the possibilities of enhancing operational efficiency, customer experience, and business models.
However, there is a lack of studies that have explored big data applications attempting to cover a wider range of transportation aspects. In this regard, Zhu et al. [26] examined the features of big data in intelligent transportation systems, the methods applied, and their applications in six subfields, namely road traffic accident analysis, road traffic flow prediction, public transportation service planning, personal travel route planning, rail transportation management and control, and asset management. Neilson et al. [27] conducted a review of big data usage obtained from traffic monitoring systems crowdsourcing, connected vehicles, and social media within the transportation domain and examined the storage, processing, and analytical techniques.
The study by Katrakazas et al. [28], conducted under the NOESIS project funded by the European Union's (EU) Horizon 2020 (H2020) program, is the only one we located that comprehensively covers the transportation field. Based on the reviewed literature, the study identified ten areas of focus that could further benefit from big data methods. The findings were validated by discussing with experts on big data in transportation. However, the disadvantage of this study lies in its dependence on a limited scope of the reviewed literature.
The majority of current review-based studies concentrate on one aspect of transportation, often analyzing a single big data source. Many of these studies rely on a limited literature dataset, and only a few have demonstrated a methodology for selecting the reviewed literature. Our review differs from existing surveys in the following ways: first, a methodology for defining the selected literature was developed, and the analysis was based on a large literature dataset. Second, this study is the only one to employ an unsupervised topic classification model to extract areas of interest and open challenges in the domain. Finally, it attempts to give an overview of the applications of big data across the entire field of transportation.
This study followed a three-stage literature analysis approach. The first stage includes defining the literature source and the papers' search procedures, as well as the “screening” to select the reviewed literature. The second stage involves statistics, which are widely employed in bibliometric analysis, to capture trends and primary insights. In the third stage, a topic classification model is applied to identify developing subfields and their applications. Eventually, the results are presented, and the findings are summarized.
The first step in this study was to define the reviewed literature. A bibliographic search was conducted using the Elsevier's Scopus database. Scopus and Web of Science (WOS) are the most extensive databases covering multiple scientific fields. However, Scopus offers wider overall coverage than WoS CC and provides a better representation of particular subject fields such as Computer Sciences [29] which is of interest in this study. Additionally, Scopus comprises 26591 peer-reviewed journals [30] including publications by Elsevier, Emerald, Informs, Taylor and Francis, Springer, and Interscience [15], covering the most representative journals in the transportation sector.
The relevant literature was identified and collected using the Scopus search API, which supports Boolean syntax. Four combinations of keywords were used in the “title, abstract, keywords” document search of the Scopus database including: “Big data” and “Transportation”, “Big data” and “Travel”, “Big data” and “Transport”, “Big data” and “Traffic”. The search was conducted in English as it offers a wider range of bibliographic sources. Only the last decade’s peer-reviewed research papers published in scientific journals and conference proceedings have been collected, written exclusively in English. Review papers and document types such as books and book chapters were excluded. As big data in transport is an interdisciplinary field addressed by different research areas, in order to cover the whole field of interest, the following subject areas were predefined in the Scopus search: computer sciences; engineering; social sciences; environmental sciences; energy; business, management and accounting. Fields considered irrelevant to the current research interest were filtered out.
The initial search resulted in a total of 5234 articles published between the period 2012–2022. The data was collected in December 2021 and last updated on the 5th of September 2023. The results were stored in a csv format, including all essential paper information such as paper title, authors’ names, source title, citations, abstracts, year of publication, and keywords. After removing duplications, a final dataset of 3532 papers remained.
The paper dataset went through a subject relevance review, at the first stage, by checking in the papers' title or keywords the presence of at least one combination of the search terms. If this condition was not met, a further review of the paper abstracts was conducted. From both stages, a filtered set of papers was selected, based on their relevance to the current study's areas of interest, associated with the search items. A total of 2671 selected papers formed the dataset which was further analyzed, evaluated, and categorized, based on clustering techniques.
Once the dataset was defined, statistical analysis was performed to identify influential journals and articles within the study field. The first task was to understand the role of the different journals and conference proceedings. Those with the most publications were listed and further analyzed according to their publication rate and research area of interest. Second, the number of citations generated by the articles was analyzed as a measure of the quality of the published studies, and the content of the most cited articles was further discussed. The above provided essential insights into research trends and emerging topics.
A crucial step in our analysis was to extract the most representative sub-topics and classify the articles into categories by applying an unsupervised topic model [16]. Initially, the Excel file with the selected papers’ data (authors, year, title, abstract, and keywords) was imported into the model. Abstracts, titles, and keywords were analyzed and text-cleaning techniques were applied. This step includes normalizing text, removing punctuations, stop-words, and words of length less than three letters, as well as the lemmatization of the words. The most popular software tools/libraries used for text mining and cleaning, as well as natural language processing (NLP) in the topic model process, are implemented in Python programming and include NLTK (https://www.nltk.org/), spaCy (https://spacy.io/), Gensim (https://radimrehurek.com/gensim/), scikit-learn (https://scikit-learn.org/stable/), and Beautiful Soup (https://www.crummy.com/software/BeautifulSoup/). NLTK is a powerful NLP library with various text preprocessing functions, while spaCy handles tokenization, stop word removal, stemming, lemmatization, and part-of-speech tagging. Gensim is a popular library for topic labeling and document similarity analysis. To process textual data, scikit-learn is a machine learning library with text preprocessing functions. Finally, Beautiful Soup is a web-based library for parsing HTML and XML documents. For the approach explained in the following sections, NLTK and Beautiful Soup were used to parse web metadata for the research papers. Moreover, bigrams and trigrams of two or three words, frequently occurring together in a document, were created.
The basic aim was to generate clusters (topics) using a topic model. The proposed model extracts representative words from the title, abstract, and keyword section of each paper, aiming to cluster research articles into neighborhoods of topics of interest without requiring any prior annotations or labeling of the documents. The method initially constructs a word graph model by counting the Term Frequency – Inverse Document Frequency (TF-IDF) [31].
The resulting topics are visualized through a diagram that shows the topics as circular areas. For the aforementioned mechanism, the Jensen-Shannon Divergence & Principal Components dimension reduction methodology was used [32]. The model is implemented in the LDAvis (Latent Dirichlet Allocation) Python library, resulting in two principal components (PC1 and PC2) that visualize the distance between the topics on a two-dimensional plane. The topic circles are created using a computationally greedy approach (the first in-order topic gets the largest area, and the rest of the topics get a proportional area according to their calculated significance). The method picks the circle centroids randomly for the first one (around the intersection of the two axes), and then the distance of the circle centroids is relevant to the overlapping of the top words according to the Jensen-Shannon Divergence model. The former model was applied for numerous numbers of topics, while its performance was experimentally verified using a combination of Naïve Bayesian Networks and a Convolutional Neural Network approach.
In the sequence of the two machine learning methodologies, supervised (Bayesian Neural Networks) and unsupervised (Deep Learning) research article classification were considered via sentiment analysis. For the supervised case, the relations among words were identified, offering interesting qualitative information from the outcome of the TF-IDF approach. The results show that the Bayesian Networks perform in accuracies near 90% of the corresponding statistical approach [33] and the same happens (somewhat inferior performance) for the unsupervised case [34]. The two methods validated the results of the TF-IDF, reaching accuracies within the acceptable limits of the aforementioned proven performances.
The TF-IDF (Term Frequency–Inverse Document Frequency) method is a weighted statistical approach primarily used for mining and textual analysis in large document collections. The method focuses on the statistical importance of a word value emanating by its existence in a document and the frequency of occurrences. In this context, the statistical significance of words grows in proportion to their frequency in the text, but also in inverse proportion to their frequency in the entire corpus of documents. Therefore, if a word or phrase appears with high frequency in an article (TF value is high), but simultaneously seldom appears in other documents (IDF value is low), it is considered a highly candidate word that may represent the article and can be used for classification [35]. In the calculation of TF-IDF, the TF word value is given as:
In Eq. 1, \(_\) denotes the frequency of the word occurrence of the term \(_\) in the document \(_\) , and the denominator of the above fraction is the sum of the occurrence frequency of all terms in the document \(_.\) At the same time, the calculation of the IDF value of a term \(_\) , is found by dividing the total number of documents in the corpus by the number of documents containing the term \(_\) , and then obtains the quotient logarithm:
$$ >_ = >\left| <\frac<<|D|>> <<\left\<This methodology evaluates the performance of TF-IDF by following a purely “machine-learning” oriented approach, which is based on the Bayesian likelihood, i.e., reverse reasoning to discover arbitrary factor occurrences that impact a particular result. These arbitrary factors correspond to the corpus terms and their frequencies within each document and corpus. The model is a multinomial naive Bayes classifier that utilizes the Scikit-learn, which is a free programming Artificial Intelligence (AI) library for the Python programming language to support: a. training text, b. feature vectors, c. the predictive model, and d. the grouping mechanism.
The results of the TF-IDF method were imported into the Bayesian classifier. More specifically, the entire dataset was first prepared to be inserted by applying noise, stop-words, and punctuation removal. The text was then tokenized into words and phrases. For topic modeling, TF-IDF was used for feature extraction, creating the corresponding vectors as features for classification. In the next step, the Naive Bayes classifier is trained on the pre-processed and feature-extracted data. During training, it learns the likelihood of observing specific words or features given each topic and the prior probabilities of each topic occurring in the training data. Not all data was used for training. The model split the data into a 70% portion used for the unsupervised training, with the remaining 30% to be used for validation. This split ratio is a rule of thumb and not a strict requirement. However, this popular split ratio is to strike a balance between having enough data for training the machine learning model effectively and having enough data for validation or testing to evaluate the model's performance. The split was used within the k-fold cross-validation to assess the performance of the model while mitigating the risk of overfitting. While the dataset is divided into k roughly equal-sized "folds" or subsets, a fixed train-test split is used within each fold. The results from each fold were then averaged to obtain an overall estimate of model performance. This approach has the advantage of assessing the model's performance in a more granular way within each fold, similar to how it is assessed in a traditional train-test split, but at the same time, it provides additional information about how the model generalizes to different subsets of the data within each fold.
In the process of text examination, a cycle of weighting is dynamically updated for cases of term recurrences in the examined documents. The documents still contain only the title, abstract, and keywords for each article. For these cases, the Bayes theorem is used:
$$P\left(c|x\right)= \frac$$where \(P(c|x)\) is the posterior probability, \(P(x|c)\) is the likelihood, \(P(c)\) is the class prior probability, and \(P(x)\) is the predictor prior probability with \(P(c|x)\) resulting from the individual likelihoods of all documents \(P\left(_|c\right),\) as depicted in Eq. (5):
$$ P\left(
This model was used as a validation method for the TF-IDF methodology, producing accuracy results reaching values of up to 91%. This value is widely acceptable for most cases of Bayesian classification and is expected to occur since prior classification has been applied [37].
This is a secondary method of TF-IDF validation, which is based on the bibliometric coupling technique. However, this technique does not use the likelihood probability of the initial classification performed by TF-IDF but rather, this classifier deploys a character-based (i.e., the alphabetical letters composing the articles’ text) convolutional deep neural network. Using the letters as basic structural units, a Convolutional Neural Network [38] learns words and discovers features and word occurrences in various documents. The model has been primarily applied for computer vision and image machine learning techniques [39], but it is easily adapted for textual analysis.
All features previously used features (title, abstract, keywords) were kept and concatenated into a single string of text, which was itself truncated to a maximum length of 4000 characters. The size of the string can be dynamically adapted for each TensorFlow-model [40] according to the GPU performance of the graphics adapter of the hardware used, and basically represents the maximum allowable length for each feature in the analysis. The encoding involved all 26 English characters, 10 digits, all punctuation signs, and the space character. Other extraneous characters were eliminated. Furthermore, keyword information was considered primary in topic classification and encoded into a vector of the proportion of each subfield mentioned in the reference list of all documents/articles used in data. The system was rectified to behave as a linear unit, producing the activation function of the deep neural network between each layer. Only the last layer of the network utilized the SoftMax activation function for the final classification. The model was trained with a stochastic gradient descent as the optimizer and categorical cross-entropy as the loss function producing inferior results when compared with the corresponding Bayesian case as expected.
To understand the role of diverse academic sources, the leading eleven journals or conference proceedings were identified (Table 1), which have published a minimum of twenty papers between 2012 and 2022 in the field of interest. According to the preliminary data, 995 journals and conference proceedings have contributed to the publication of 2671 papers. Eleven sources have published 553 articles, representing the 2100% of all published papers.
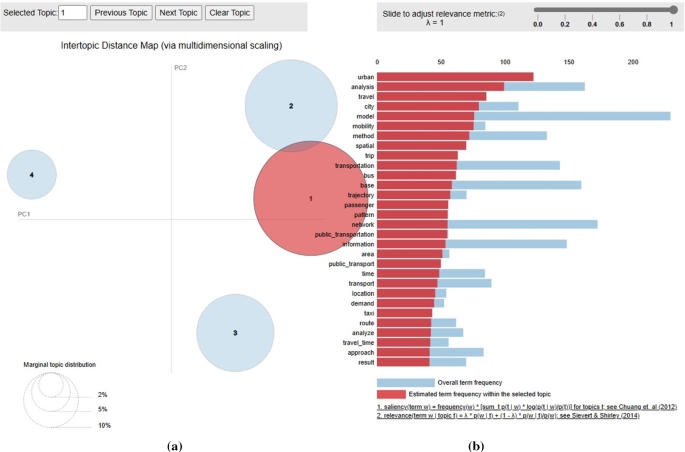
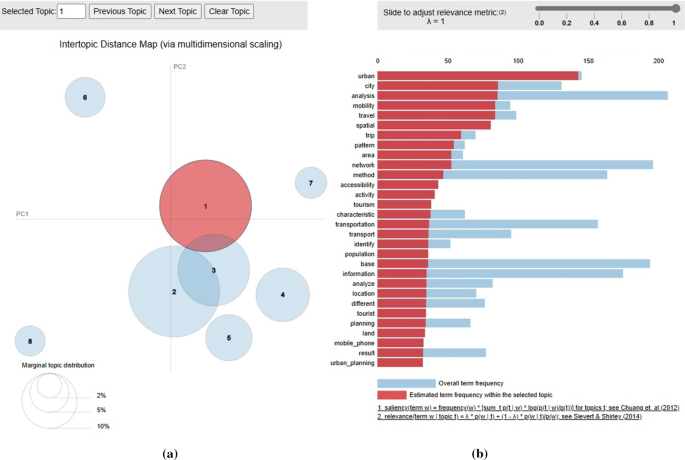
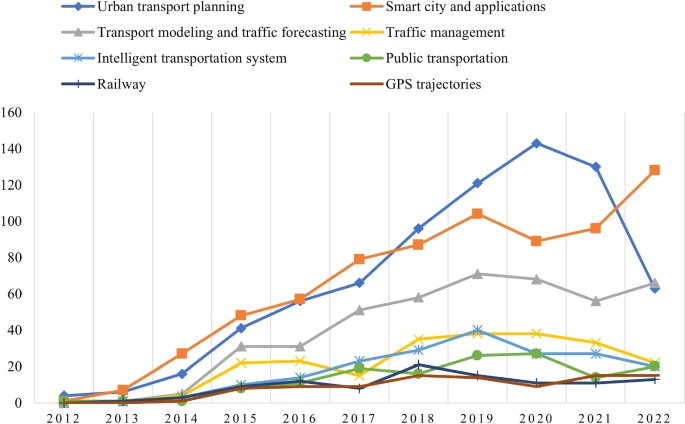
As shown in the analysis, there is an increasing research interest in big data usage in the transportation sector. It is remarkable that besides computer science journals and conferences, transportation journals have also published relevant articles representing a notable proportion of the research and indicating that transportation researchers acknowledge the significance of big data and its contribution to many aspects of transportation. According to the citation analysis, three research areas emerged among the most influential studies: (1) traffic flow prediction and management (2) new challenges of the cities (smart cities) and new technologies (3) urban transport planning and spatial analysis.
Following the topic model results, eight paper groups are proposed. Most articles (742) fall into the topic of “urban transport planning”. Several representative papers in this area attempted to estimate travel demand [5], analyze travel behavior [6], or investigate activity patterns [51] by utilizing big data sourced primarily from mobile phone records, social media, and smart card fare collection systems.
Big data also has significant impacts on “smart cities and applications”. Topic 2 is a substantial part of the dataset, which includes 723 papers. They mainly refer to new challenges arising from big data analytics to support various aspects of the city, such as transportation or energy [44] and investigate big data applications in intelligent transportation systems [26] or in the supply chain and logistics [54].
A total of 438 papers were categorized in Topic 3 labeled as “traffic flow forecasting and modeling”. The majority applied big data and machine learning techniques to predict traffic flow [41,42,43]. In risk assessment, Chen et al. [55] proposed a logit model to analyze hourly crash likelihood, considering temporal driving environmental data, whereas Yuan et al. [56] applied a Convolutional Long Short-Term Memory (ConvLSTM) neural network model to forecast traffic accidents.
Among the papers, a special focus is given to different aspects of “traffic management” (231 papers), largely utilizing real-time data. Shi and Abdel-Aty [7] employed random forest and Bayesian inference techniques in real-time crash prediction models to reduce traffic congestion and crash risk. Riswan et al. [57] developed a real-time traffic management system based on IoT devices and sensors to capture real-time traffic information. Meanwhile, He Z. et al. [58] suggested a low-frequency probe vehicle data (PVD)-based method to identify traffic congestion at intersections to solve traffic congestion problems.
Topic 5 includes 194 records on “intelligent transportation systems and new technologies”. It covers topics such as Internet of Vehicles [48, 59, 60], connected vehicle-infrastructure environment [61], electric vehicles [62], and the optimization of charging stations location [63], as well as autonomous vehicles (AV) and self-driving vehicle technology [64].
In recent years, three smaller and more specialized topics have gained interest. Within Topic 6, there are 144 papers discussing public transport. Tu et al. [65] examined the use of smart card data and GPS trajectories to explore multi-modal public ridership. Wang et al. [66] proposed a three-layer management system to support urban mobility with a focus on bus transportation. Tsai et al. [67] applied simulated annealing (SA) along with a deep neural network (DNN) to forecast the number of bus passengers. Liu and Yen [68] applied big data analytics to optimize customer complaint services and enhance management process in the public transportation system.
Topic 7 contains 104 papers on how big data is applied in “railway network”, focusing on three sectors of railway transportation and engineering. As mentioned in Ghofrani et al. [24], these sectors are maintenance [69,70,71], operation [72, 73] and safety [74].
Topic 8 (95 papers) refers mainly to data deriving from “GPS trajectories”. Most researchers utilized GPS data from taxis to infer the trip purposes of taxi passengers [75], explore mobility patterns [76], estimate travel time [77], and provide real-time applications for taxi service improvement [78, 79]. Additionally, there are papers included in this topic that investigate ship routes. Zhang et al. [80] utilized ship trajectory data to infer their behavior patterns and applied the Ant Colony Algorithm to deduce an optimal route to the destination, given a starting location, while Gan et al. [81] predicted ship travel trajectories using historical trajectory data and other factors, such as ship speed, with the Artificial Neural Network (ANN) model.
An extensive overview of the literature on big data and transportation from 2012 to 2022 was conducted using bibliometric techniques and topic model classification. This paper presents a comprehensive methodology for evaluating and selecting the appropriate literature. It identifies eight sub-areas of research and highlights current trends. The limitations of the study are as follows: (1) The dataset came up by using a single bibliographic database (Scopus). (2) Research sources, such as book chapters, were excluded. (3) Expanding the keyword combinations could result in a more comprehensive review. Despite these limitations, it is claimed that the reviewed dataset is representative, leading to accurate findings.
In the process of selecting the suitable literature, various criteria were defined in the Scopus database search, including the language, subject area, and document type. Subsequently, duplicate and non-scientific records were removed. However, the last screening of the titles and abstracts to determine the relevance of the studies to the paper’s research interests was conducted manually. This could not be possible for a larger dataset. Additionally, as previously stated, the dataset was divided into eight distinct topics due to multiple overlaps caused by an increase in the number of topics. Nevertheless, the topic of “smart cities and applications” remains broad, even with this division. This makes it challenging to gain in-depth insights into the field and identify specific applications, unlike in “transport planning”, where two additional topics were generated by the further classification. Applying the classification model to each topic separately could potentially overcome these constraints by revealing more precise applications and filtering out irrelevant studies.
Despite the above limitations and constraints, the current study provides an effective methodology for mapping the field of interest as a necessary step to define the areas of successful applications and identify open challenges and sub-problems that should be further investigated. It is worth mentioning that there is an intense demand from public authorities for a better understanding of the potential of big data applications in the transport domain towards more sustainable mobility [82]. In this direction, our methodology, along with the necessary literature review and discussion with relevant experts, can assist policymakers and transport stakeholders in identifying the specific domains in which big data can be applied effectively and planning future transport investments accordingly.
Having defined the critical areas of big data implementation within transportation, trends, and effective applications, the aim is to conduct a thorough literature review in a subarea of interest. This will focus on transport planning and modeling, and public transportation, which appears to be highly promising, based on our findings. A more extensive literature review and content analysis of key studies are crucial to further examine open challenges and subproblems as well as to investigate the applied methodologies for possible revision or further development.
The current study provides a broad overview of the applications of big data in transport areas, which is the initial step in understanding the characteristics and limitations of present challenges and opportunities for further research in the field.
This research is financed by the Research, Innovation and Excellence Program of the University of Thessaly.